From the Terminal
PHP attributes are so awesome I just had to add attribute based field mapping to my ORM
I wrote this post to talk about the architectural decisions I had to make in upgrading my ORM recently to PHP8 as well as the general justification for using an ORM in the first place as a query writer, runner, and object factory and why I consider attributes to be the holy grail of ORM field mapping in PHP.
Writing Queries
I've always been fascinated with moving data in and out of a database. I've been at this from PHP4 days, you know. As hard as it is to believe even back then we had a testable, repeatable, and accurate way of pushing data into and out of a database. I quickly found myself writing query after query.... manually. At the time there was no off the shelve framework you could just composer require. So I found myself thinking about this problem again and again and again and again.
Put simply when you write SQL queries you are mapping variable values in memory to a string. If you are one of those people that claims that an ORM is bloat you'll find yourself writing hundreds of queries all over your projects.
If you've ever imploded an array by a "','" but then ended up doing it in dozens or hundreds or thousands of places the next logical step is to stop rewriting your code and write a library.... and hence an ORM is born. An ORM is an absolute statement; that "I will not rewrite code for handling a datetime" and then actually following through.
To make this happen you must write some sort of translation layer from PHP types to SQL types. In most ORMs this is called mapping.
Before PHP8 the typical thing to do was to use a PHP array defined statically containing all that information. Like this. In fact this is from Divergence from before version 2.
public static $fields = [
'ID' => [
'type' => 'integer',
'autoincrement' => true,
'unsigned' => true,
],
'Class' => [
'type' => 'enum',
'notnull' => true,
'values' => [],
],
'Created' => [
'type' => 'timestamp',
'default' => 'CURRENT_TIMESTAMP',
],
'CreatorID' => [
'type' => 'integer',
'notnull' => false,
],
];But this kinda sucks. There's no way to do any auto complete and it's just generally a little bit slower.
A few frameworks decided to support mapping using annotations (an extended PHPDoc in PHP comments) and even yaml field maps but those are all just bandaids on the real problem. Which was that there was no real way to provide proper field definitions using the raw language's tokens, instead relying on the runtime to store and process that information.
Attributes
So that's my long winded explanation about why my absolute favorite feature of PHP 8 is attributes. Specifically for ORM field mapping. Yea really.
#[Column(type: "integer", primary:true, autoincrement:true, unsigned:true)]
protected $ID;
#[Column(type: "enum", notnull:true, values:[])]
protected $Class;
#[Column(type: "timestamp", default:'CURRENT_TIMESTAMP')]
protected $Created;
#[Column(type: "integer", notnull:false)]
protected $CreatorID;This is sooooo much cleaner. Look how awesome it is. Suddenly I have auto complete for field column definitions right in my IDE!

Now the code is cleaner and easier to follow! You've even got the ability to type hint all your fields.
Once we take field mapping to it's logical conclusion it becomes practical to simply map as many database types as we can into the ORM. We can even try to support all of the various field types that could be used in SQL and represented somehow in PHP. Of course to make this happen it becomes necessary to tell the framework some details about the database field type you decide to use. For example you can easily see yourself using a string variable type for varchar, char, text, smalltext, blob, etc but most ORMs aren't typically smart enough to warn you when you inevitably make a mistake and try to save your larger than 256 character string to a varchar(255). If you were to build all of this yourself you would invariably find yourself creating your own types for your ORM and doing a translation from language primitive to database type and back just like I am here. This gets even more complex when an ORM decides to support multiple database engines. Once this becomes more fleshed out you can even have your ORM write the schema query and automatically create your tables from your code.
Here for example I'm gonna go ahead and create a Tag class and then save something.
class Tag extends Model {
public static $tableName = 'tags';
protected $Tag; // this will be a varchar(255) in MySQL, a string in PHP
}
$myTag = new Tag();
$myTag->Tag = 'my tag';
$myTag->save();
With these few simple lines of code we've created a tags table and saved a new Tag "my tag" into our new table. The framework automatically detected the table was missing during the save and created it and then followed through by running the original save. Excellent for bootstrapping new projects or installing software.
Protected? Magic Methods
Traditionally it's common to think that __get and __set are triggered only when a property is undefined. However it is also triggered if you try to access a protected property from outside of the model. When you access a protected attribute from outside of the object it will always trigger __get when retrieving and __set when setting. For this reason I decided to use protected attributes in a Model for mapping.
The way in and out allows us to do some type casting. For example Divergence supports reading a timestamp in Y-m-d H:i:s, unix timestamp, and if it's a string that isn't Y-m-d H:i:s it will try running it through strtotime() before giving up. But that will only ever happen when __set is called thereby starting the chain of events leading to the necessary type casting for that field type. Unfortunately the downside to using a protected in this context is that when you need to access a field inside the object you can't use $this->Tag = 'mytag'; because it won't trigger __set and so what's gonna happen is you will end up messing with the internal data of that field incorrectly. So for the specific context where you're working with the field directly inside of the object itself you should actually use setValue and getValue instead. Frankly you can use __set and __get directly but let's be civilized here. This caveat is why I would like to see the ability for PHP to have __set and __get triggerables configurable to do so on existing object members.
Relationships.
But wait. There's more! Now with the ability to use Attributes for field definitions we can use them for relationship definitions as well.
#[Relation(
type: 'one-one',
class: User::class,
local: 'CreatorID',
foreign: 'ID'
)]
protected $Creator;
#[Relation(
type: 'one-many',
class: PostTags::class,
local: 'ID',
foreign: 'BlogPostID'
)]
protected $Tags;Relationships take Attributes to the next level.
$this->getValue('Tags');This is all you need to pull all the Tags as an array. Most relationship types can be easily expressed in this format.
$Model->Tags // also works but only from "outside"You can run it like this as well from outside of the Model.
PHP in 2023 is blindingly fast.
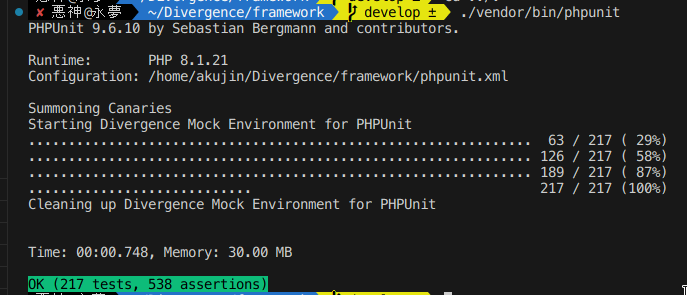
Today the entire suite of tests written for Divergence covering 82% of the code completes in under a second. Some of these tests are generating thumbnails and random byte strings for mock data.
For reference in 2019 the same test suite clocked in at 8.98 seconds for only 196 tests. By the way these are database tests including dropping the database and creating new tables with data from scratch. The data is randomized on every run.
Performance
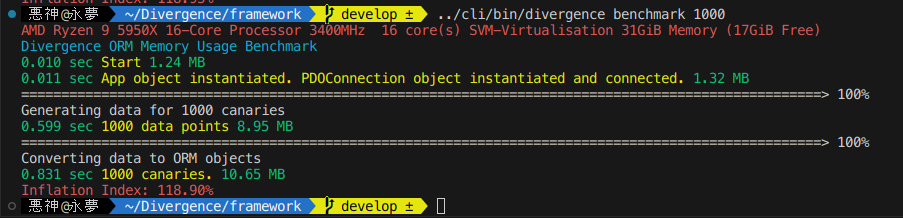
What you are seeing is [time since start] [label] [memory usage] at print time.
The first part where it generates 1000 data points is all using math random functions to generate random data entirely in raw none-framework PHP code. Each Canary has 17 fields meant to simulate every field type available to you in the ORM. Generating all 17 1000 times takes a none trivial amount of time and later when creating objects from this data it must again process 17,000 data points.
Optimizing the memory usage here will be a point of concern for me in future versions of the ORM.
All the work related to what I wrote about in this post is currently powering this blog and is available on Github and Packagist.
How I gamified unit testing my PHP framework and went from 0% unit test coverage to 93% in 30 days
In 2018 I was taking a break from work. I wanted to upgrade my skills while looking for new opportunities. My previous job was working in a NodeJS environment which I certainly enjoy in many ways but PHP is actually my favorite language to work with so I wanted to challenge myself to learn something new.
I had two goals really. The first was to learn. I wanted to see what continuous integration was actually all about. The second was to prove the rock solid design of the ORM library I've been using for the past five years. It was passed around by a few local developers I knew but using it in production on new projects became an increasingly hard battle as most people wanted to use other ORMs that were more popular. It felt like without unit tests and a code coverage badge and a page on packagist I had no legitimacy. With that in mind I got to work.
With this post I hope to write down what I learned in a clear, concise, and easy to understand way for moderately experienced PHP developers and for myself.
Code Coverage
Code coverage is a line by line yes/no report from PHPUnit that simply says if that line has been tested or if it has not. You can get a code coverage report on your own computer just by running PHPUnit with XDebug enabled. Just add the command line switch --coverage-clover clover.xml when you run PHPUnit.

Here you can see I'm telling phpunit where to put the code coverage report. You will need Xdebug as well for the feature to be available. A clover.xml file by itself though is just raw data and without a proper interface to view it you won't really be able to make much use of it.
View the Code Coverage Report
One website which provides this is Codecov.io
They give you a simple to use bash install script.
You can run it right now with the report you already generated right in the terminal.

You should probably sign up at this point and claim your free private repository. If your project is open-source you can have as many as you want!
Once signed up you will find the token in the repository settings. They give you a few ways to specify the token there.

Now you can run the report uploader script from above again.

Now that it uploaded you can take a look at the report.

As you can see my initial commit had terrible code coverage. The code was still not even organized as per PSR-4 and PHP League standards but at least I had base line and there's no where to go but up.
The PHP League
The PHP League of Extraordinary Packages make a slew of excellent packages but they also provide a skeleton template available in this Git repository that documents the proper modern way of organizing a PHP project. It was invaluable to me as a reference.
It shows you how to configure badges, continuous integration, organize your source code, and lots of other best practices.
Continuous Integration
Now that we know the code coverage report works we can setup continuous integration. I'd recommend TravisCI but if you have Bitbucket premium it comes with 500 free minutes of their continuous integration solution called Pipelines. Pipelines and TravisCI are basically just plugins for Github or Bitbucket or any other host of your Git repository. They get event hooks when your code gets pushed to your Git host and then they run a bash script in a container with your code. You can then run tests, do builds, and setup other automated solutions for your source code. But how you ask? Well there's a YAML file you have to create. In this example I will show my Travis file. The source is available here.
language: php
php:
- '7.1'
- '7.2'
addons:
apt:
sources:
- mysql-5.7-trusty
packages:
- mysql-server
- mysql-client
before_install:
#- sudo mysql -e "use mysql; update user set authentication_string=PASSWORD('divergence_tests') where User='root'; update user set plugin='mysql_native_password';FLUSH PRIVILEGES;"
#- sudo mysql_upgrade
#- sudo service mysql restart
- mysql -e 'CREATE DATABASE IF NOT EXISTS test;'
install:
# Install composer packages
- travis_retry composer update --no-interaction --no-suggest
- travis_retry composer install --no-interaction --no-suggest
# Install coveralls.phar
- wget -c -nc --retry-connrefused --tries=0 https://github.com/php-coveralls/php-coveralls/releases/download/v2.0.0/php-coveralls.phar -O coveralls.phar
- chmod +x coveralls.phar
- php coveralls.phar --version
before_script:
- mkdir -p build/logs
- ls -al
script:
- ./vendor/bin/phpunit --coverage-clover build/logs/clover.xml
after_success:
# Submit coverage report to Coveralls servers, see .coveralls.yml
- travis_retry php coveralls.phar -v
# Submit coverage report to codecov.io
- bash <(curl -s https://codecov.io/bash)
# Tell Travis CI to monitor only 'master' branch
branches:
only: master
# Specify where the cache is so you can delete it via the travis-ci web interface
cache:
directories:
- vendor
- $HOME/.cache/composerThis file basically tells Travis what to do.
- Which versions of PHP to test with.
- Which branches of the git repo to run against.
- Sets up the localhost MySQL environment for our PHPUnit tests in the container.
- Runs composer dependency installer
- Runs PHPUnit
- Uploads the code coverage report.
The best part? You get an email at the end with what got fixed or any new problems. TravisCI also runs a rudimentary static analyzer on your code bringing up problems with the source as well as your PHPDoc notation which adds even more added value to having your unit tests run automatically every time you update a given branch.
In Github you even get this view available to you all in one place.

The Road to 90%
Initially you come to the realization that your ability to increase the score through your simple and basic helper classes lets you score a few easy wins early on. Ripping out old, unused, verbose, and unclean code also lowers your total code count thereby increasing your overall coverage score. Sometimes you actually have to edit your code to make it easier to test. Standalone global code in PHP files becomes even more onerous as testing that code becomes next to impossible. Let's take a look at a few examples.
Editing your code to make it easier to test.
Here I need to fake the stream php://input which is what we parse for raw JSON data sent via POST. Doable but only by creating your own fake stream and at a different address.

But it's okay because it enabled this simple test. Which increased the coverage of that one file by 13.33%. By the way virtual streams are pretty awesome. Check out the test below.
/**
* @covers Divergence\Helpers\JSON::getRequestData
*/
public function testGetRequestData()
{
$json = '{"array":[1,2,3],"boolean":true,"null":null,"number":123,"object":{"a":"b","c":"d","e":"f"},"string":"Hello World"}';
vfsStream::setup('input', null, ['data' => $json]);
JSON::$inputStream = 'vfs://input/data';
$x = json_decode($json,true);
$A = JSON::getRequestData();
$B = JSON::getRequestData('object');
$this->assertEquals($A, $x);
$this->assertEquals($B, $x['object']);
}Ripping Out Old Code
Here I found a function that was previously used to manually prettify JSON used way back when PHP didn't have this functionality built in. Sometimes it's sad to delete old code. Especially when it's will written, clean, and easy to understand. But sometimes it's just time to let it go and let someone else worry about it.

Lets just say I cut a lot of random old code. This obviously had a great impact on the readability and cleanliness of the code going forward.
What I did for Database Unit Testing
Eventually I ran out of low hanging fruit testing things that had nothing to do with the database and then... it was time for the database. A number of issues came up.
- A test database would need to be created on my laptop that mirrors the TravisCI config to avoid having to write extra logic. I added a new 'testing' default config to the default database config that comes with the framework.
- I needed to add some bash terminal commands to the TravisCI file above to make it reset the database every time.
- I need a way to run some code the unit tests need to run before all the unit tests would begin to setup a bunch of fake data.
To solve this I created a class which implements PHPUnit's PHPUnit_TestListener interface. I previously wrote a post on doing this in detail.



So here we initialize our mock application and set the database connection to use the tests-mysql config.
App::setUp is actually where the mock data is created.
Fake it till you make test it
To make this database testing thing actually work I actually made a fake site that would live in the PHPUnit environment. I gave it a separate namespace in the tests namespace.

The App class from earlier? You can view it here.

As I wrote more unit tests I added more and more Tag creation stuff to this function. As I created more and more mock data attacking the more and more complex situations in my tests became easier and easier.
Lowering Code Complexity
As you get further and further into testing your code you will come to some code which has lots of complex conditional statements with multiple conditions which might potentially have any n-number of possible combinations. By breaking out your code into ever smaller and smaller methods it is possible to make every method have a very low number of combinations hopefully in the single digits.
For example the increased conditional complexity of the code below make it difficult to get tests which achieve 100% unit test coverage because you need to provide every possible permutation of conditionals and if there are more obviously there could be more conditions.

I changed the above to be a switch($options['type']) instead and broke out each type into it's own function. The new functions become much easier to test with fewer conditional permutations to keep track of.


Writing tests for these much simpler functions becomes almost trivial and the code looks much cleaner too.